はじめに
この記事はAI Shift Advent Calendar 2024の24日目の記事です。
初めまして!
早稲田大学修士2年生の村田栄樹です。
11月と12月の2ヶ月間、株式会社AI Shiftで ML/DS として内定者バイトをしています。
大学では普段、自然言語処理の研究をしていて、今回のバイト期間中も自然言語処理周りのタスク(特にRAG関連)に取り組みました。
せっかくバイト期間中にアドベントカレンダーがあるので、バイト中に取り組んだタスクや感想をまとめさせていただきます!
タスクの内容について技術的な内容を含めて書いた後に、内定者バイトを通じての感想をまとめたいと思います。
クリスマスイブ担当という大役(タスクが終わらないことを恐れて後半担当になりました)ですが、RAGおよびAI Shiftに興味がある人にとって読み応えのある記事となっていることを祈っています。
タスク: クエリ書き換え
背景
RAG(Retrieval Augmented Generation)自体の詳しい解説は他の記事に譲りますが、再学習をせずに望んだ知識をLLMに与えることができるため、注目度の高い技術となっています。
AI ShiftでもRAGを用いたプロダクトを開発しており、その精度を改善することが私のタスクでした。
一般的なRAGの問題点として、以下のようなことが挙げられます。
- ユーザクエリと検索対象のドキュメントが意味空間として近くない
- BM25などの表層検索の場合、タイポや類語に弱い
- 検索された結果やそれを基にした生成に対する評価が難しい
特に1つ目と2つ目の問題点に対して取り組むことにしました。
具体的には、クエリを書き換えることによりドキュメントとの意味的な距離を近づけ、検索精度を改善する手法の検証および実装です。
関連研究
クエリとドキュメントの意味的な距離を近づける手法は、
- 埋め込みモデルの訓練時に、クエリとドキュメントのようなペアを正例として入れることで、対応するクエリの埋め込みをドキュメントの埋め込みに近づける
- クエリもしくはドキュメントをテキストとして書き換え、表層的に意味を近づける
の2つのタイプに大別されます。
1つ目のタイプに分類されるようなモデルとしては、以下のようなものが知られています。
- Multilingual-E5
- 多言語に対応した事前学習済み埋め込みモデル
- 学習時に"query:"と"passage:"という接頭辞を使用して、意味空間をアライメントする
- Ruri
- 日本語に特化した事前学習済み埋め込みモデル
- E5と同様に、学習時に"クエリ:"と"文章:"という接頭辞を使用する
- Vertex AI エンベディングモデル
- タスクタイプと呼ばれるパラメータを指定することにより、タスクに合わせて埋め込みベクトルの品質を向上させる
- 2024年12月現在、4つの問題設定に対して7種類のタスクタイプが用意されている

図引用: https://cloud.google.com/vertex-ai/generative-ai/docs/embeddings/task-types?hl=ja
2つ目の書き換えの例としては、以下のようなものがあります。
- Rewrite-Retrieve-Read
- RAG従来のRetrieve-then-Readではなく、クエリを書き換えたのちに検索をすることを提案
- 以下のようなIn-Context Learningで実現
Think step by step to answer this question, and provide search engine queries for knowledge that you need. Split the queries with ’;’ and end the queries with ’**’.
Question: What profession does Nicholas Ray and Elia Kazan have in common?
Answer: Nicholas Ray profession;Elia Kazan profession**
...
Question: {x}
Answer: - 前述した問題点の中では1つ目(ユーザクエリと検索対象のドキュメントが意味空間として近くない)というより2つ目の問題点(BM25などの表層検索の場合、タイポや類語に弱い)に対する手法ですが、書き換えの手法ということでここで紹介しました
- HyDE (Hypothetical Document Embeddings)
- LLMでクエリに対する擬似的な回答を生成することで表層的な意味を近づける
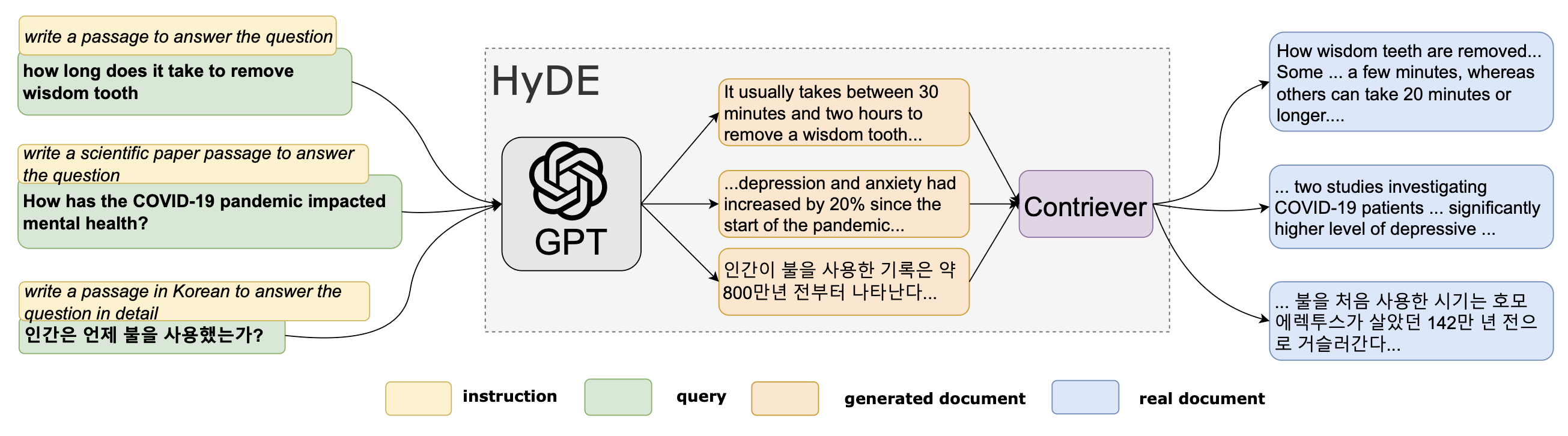
図引用: https://arxiv.org/abs/2212.10496
- LLMでクエリに対する擬似的な回答を生成することで表層的な意味を近づける
改めて私はクエリ書き換えによってRAGの精度を改善する2つ目のタイプについて取り組むことにしました。理由としては、(1)クエリの書き換えはさまざまなユースケースに対して汎用性が高いと考えたことと、(2)プロダクトではAPI経由で埋め込みモデルを使用しているため介入の余地がないことがありました。
(1)は、対象ドキュメント内の製品名の変更(例:「Tポイント」→「Vポイント」)や異なる言語のクエリなど個別のユースケースに同じ枠組みで対応できるという利点です。
精度検証実験(通常データ)
タスク決定後、クエリの書き換えが実際の業務で使用されるデータでどの程度有効かを確かめるために精度検証実験を実施しました。
手法
関連研究のサーベイを参考に以下の3つの手法を検証します。いくつかのモデルを事前実験で検証しましたが、費用面と性能を鑑みてすべて Open AI の GPT-4o-mini を用いて書き換えを実行します。また、各手法に対して、ABEMAの料金はいくらですか?というクエリに対する書き換え例を示します。
- paraphrase (Para)
- 質問を異なる単語を含むように言い換える
- プロンプト:
与えられた質問を意味的に同じ内容で使用されている単語が異なるものに書き換えてください。ただし、書き換えた質問のみを出力してください。 - 書き換え例:
ABEMA TVの月額は?
- keyword (Key)
- 質問からキーワードを取り出して検索エンジン-likeなクエリにする
- プロンプト:
全文検索のためのキーワードを抽出してください。ただし、キーワードのみを半角空白区切りで出力してください。 - 書き換え例:
ABEMA 料金
- pseudo_answer (HyDE)
- 疑似的な回答を生成する。クエリ空間からドキュメント空間に近づけることでヒットしやすくする。
- プロンプト:
与えられた質問への疑似的な回答を生成してください。回答はFAQのページのコンテンツのように書いて、回答部分のみを100字程度で簡潔に出力してください。 - 書き換え例:
ABEMA TVは月額580円で利用できます。また、無料で利用できるコンテンツも用意されています。
また、リトリーブの設定は以下の通りです。
- 入力: 元のクエリと言い換えられたクエリ(1つ以上)
- それぞれのクエリについてリトリーブ
- 指定されたドキュメント数(10件)に50を加えた個数を検索
- 検索手法
- vector: 埋め込みベクトルのコサイン類似度
- surface: BM25
- それぞれの検索結果の逆順位の和でソート
- 指定された文書数(10件)分のドキュメントを検索結果とする
データセット
以下のような設定のデータセットを使用しました。
- 検索対象のドキュメント: 社内の実データ
- 精度検証用の3つ組
- LLMで検索対象の実データを入力として3つ組{Query, Gold Answer, Gold Document}を生成
- Query: RAGシステムに入力する質問文
- Gold Answer: 対象ドキュメントを入力した状態でLLMが生成したQueryに対する回答
- Gold Document: 上記2つを作成するときに入力したドキュメント
評価指標
RAGシステムのうち、検索パートと生成パートそれぞれを以下のように評価します。
- 検索パート
- HR@k (Hit Rate at k): k位以内にGold Documentがある割合
- MRR (Mean Recipirocal Rank): 順位の逆数の平均
- 追加費用: クエリ書き換えにかかったコスト(米ドル/クエリ)
- 生成パート
- LLMEval: GPT-4oによる5段階評価 (Query, Gold Answer, システムの回答を入力)
結果
検索手法ごとの結果を表1,2に示します。
書き換えを行わないベースラインと、各手法をそれぞれ用いた場合、3つの手法を同時に用いた場合の5つの設定について表示しています。
表1. vector検索での結果
| Para | Key | HyDE | HR@1 | HR@3 | HR@5 | HR@10 | MRR | 追加費用 | LLMEval |
|---|---|---|---|---|---|---|---|---|---|
| ❌ | ❌ | ❌ | 0.444 | 0.622 | 0.697 | 0.763 | 0.545 | 0 | 4.145 |
| ✅ | ❌ | ❌ | 0.419 | 0.602 | 0.693 | 0.759 | 0.527 | 3.17E-05 | 4.174 |
| ❌ | ✅ | ❌ | 0.444 | 0.651 | 0.714 | 0.776 | 0.556 | 2.40E-05 | 4.141 |
| ❌ | ❌ | ✅ | 0.444 | 0.639 | 0.705 | 0.780 | 0.555 | 6.87E-05 | 4.178 |
| ✅ | ✅ | ✅ | 0.452 | 0.656 | 0.710 | 0.772 | 0.561 | 9.71E-05 | 4.220 |
vector 検索では Keyword手法 および HyDE を使用した場合に検索精度が向上し、すべての手法を同時に実行した時に最も良い結果を得ました。
LLMEval でもすべての手法を同時に実行した場合が最も高得点です。
高性能なLLMをAPI経由で簡単に使える近年では、やはりRAGのボトルネックは検索パートにあるな、と感じています。
一方で、Paraphrase 手法では精度が低下しています。これはクエリが Gold Document から作成されており、一字一句同じ文言がクエリと Gold Document に含まれているため書き換えによって精度が低下したと考えられます。実クエリでは曖昧なものやタイポ、類義語などが含まれるため改善する可能性があると考えています。
またコスト面からも、1クエリあたり最大で約$0.0001(~¥0.015)と十分安価に精度向上が実現できたと言えます。
さらに結果には載せていませんが、精度検証段階では並列化していなかったため、書き換え手法を増やすにつれて線形に生成が始まるまでのレイテンシが増加するという問題がありました。本番実装の段階では非同期処理により、書き換え手法の個数によらず一定のレイテンシを実現することができました。
表2. surface検索での結果
| Para | Key | HyDE | HR@1 | HR@3 | HR@5 | HR@10 | MRR | 追加費用 | LLMEval |
|---|---|---|---|---|---|---|---|---|---|
| ❌ | ❌ | ❌ | 0.315 | 0.481 | 0.581 | 0.664 | 0.419 | 0 | 4.054 |
| ✅ | ❌ | ❌ | 0.295 | 0.423 | 0.531 | 0.631 | 0.387 | 3.17E-05 | 4.058 |
| ❌ | ✅ | ❌ | 0.332 | 0.498 | 0.602 | 0.689 | 0.440 | 2.41E-05 | 4.141 |
| ❌ | ❌ | ✅ | 0.224 | 0.407 | 0.502 | 0.643 | 0.340 | 6.87E-05 | 4.058 |
| ✅ | ✅ | ✅ | 0.295 | 0.461 | 0.535 | 0.685 | 0.405 | 9.71E-05 | 4.071 |
surface 検索では Keyword 手法のみで改善が見られました。
これは(stop wordなどがあるにしても)、クエリ側で余分な情報を減らすことで表層検索によってヒットしやすい状況を作ることができたためだと考えています。
ただし、surface 検索ではベースラインを含め全体的に精度が低く、文埋め込みの性能の高さを痛感しました。
また、Keyword 以外の手法は精度が悪化しており、書き換え手法と検索手法の組み合わせは慎重に選択する必要も感じています。
精度検証実験(低品質データ)
通常データでの精度検証実験では疑似データにおいて、クエリ書き換えによって検索精度がやや改善することを確かめました。
一方で実データを眺める中で、実際のプロダクトが受け付けるユーザのクエリはタイポが含まれたり完全な文でなかったりと疑似データとは性質が異なることに気づきました。
そこで質の低いクエリを含むデータに対して、クエリ書き換えがベースラインと比較してどのような挙動をするかを検証します。
実験設定
後述するクエリを除いて、精度検証実験(通常データ)と同様の設定で実験します。
また、検索手法によって傾向に差が見られなかったため、vector 検索の結果のみを示します。
質の低いクエリの準備
以下の3つのタイプのミスが含まれるようなクエリを元のデータセットをベースとして作成します。
作成にはLLMを使用しました。
- タイポ: 製品の名前などの固有名詞にタイポが含まれるもの
- 文法ミス: 助詞や語順が誤っているもの
- キーワード羅列: 完全な文ではなく、検索エンジンに入力するようなキーワードの羅列
結果
上記の3つのタイプのミスが含まれるようなクエリに対する結果を表3~5にそれぞれ示します。
表3. タイポを含むクエリに対する結果
| Para | Key | HyDE | HR@1 | HR@3 | HR@5 | HR@10 | MRR | 追加費用 | LLMEval |
|---|---|---|---|---|---|---|---|---|---|
| ❌ | ❌ | ❌ | 0.390 | 0.598 | 0.660 | 0.734 | 0.503 | 0 | 4.112 |
| ✅ | ❌ | ❌ | 0.398 | 0.593 | 0.651 | 0.734 | 0.506 | 3.22E-05 | 4.095 |
| ❌ | ✅ | ❌ | 0.423 | 0.614 | 0.685 | 0.755 | 0.528 | 2.49E-05 | 4.129 |
| ❌ | ❌ | ✅ | 0.411 | 0.610 | 0.664 | 0.739 | 0.520 | 6.84E-05 | 4.137 |
| ✅ | ✅ | ✅ | 0.407 | 0.631 | 0.672 | 0.759 | 0.526 | 9.70E-05 | 4.154 |
表4. 文法ミスを含むクエリに対する結果
| Para | Key | HyDE | HR@1 | HR@3 | HR@5 | HR@10 | MRR | 追加費用 | LLMEval |
|---|---|---|---|---|---|---|---|---|---|
| ❌ | ❌ | ❌ | 0.427 | 0.618 | 0.705 | 0.763 | 0.536 | 0 | 4.174 |
| ✅ | ❌ | ❌ | 0.419 | 0.614 | 0.697 | 0.759 | 0.532 | 3.23E-05 | 4.162 |
| ❌ | ✅ | ❌ | 0.436 | 0.647 | 0.714 | 0.772 | 0.551 | 2.44E-05 | 4.191 |
| ❌ | ❌ | ✅ | 0.440 | 0.656 | 0.693 | 0.772 | 0.553 | 6.89E-05 | 4.203 |
| ✅ | ✅ | ✅ | 0.440 | 0.656 | 0.685 | 0.780 | 0.556 | 9.76E-05 | 4.278 |
表5. キーワード羅列クエリに対する結果
| Para | Key | HyDE | HR@1 | HR@3 | HR@5 | HR@10 | MRR | 追加費用 | LLMEval |
|---|---|---|---|---|---|---|---|---|---|
| ❌ | ❌ | ❌ | 0.465 | 0.672 | 0.730 | 0.788 | 0.575 | 0 | 4.225 |
| ✅ | ❌ | ❌ | 0.440 | 0.651 | 0.722 | 0.780 | 0.555 | 2.35E-05 | 4.216 |
| ❌ | ✅ | ❌ | 0.469 | 0.668 | 0.730 | 0.788 | 0.577 | 1.97E-05 | 4.212 |
| ❌ | ❌ | ✅ | 0.456 | 0.656 | 0.714 | 0.784 | 0.563 | 6.55E-05 | 4.245 |
| ✅ | ✅ | ✅ | 0.461 | 0.664 | 0.722 | 0.793 | 0.573 | 8.88E-05 | 4.232 |
まず通常のデータを使用した場合(表2)と比較して、ベースラインの検索精度が低下していることがわかります(キーワード羅列クエリを除く)。
MRRについてみると、タイポを含む場合が0.042ポイント、文法ミスを含む場合が0.009ポイント減少しています。
クエリ書き換えでも、通常のデータを使用した場合と比較すると検索精度が下がっているものの、同じデータに対してはMRRやHR@10においてベースラインをおよそ上回っています。
クエリ書き換え特有の頑健性のようなものは観測できませんでしたが、クエリ書き換えはミスを含むデータでも同様に有効であることを確認できました。
キーワード羅列クエリでは、通常のデータを使用した場合(表2)と比較して、全体的に検索精度が上がるという結果になりました。ベクトル検索を使用する場合でも、検索エンジンに入れるようなキーワードの羅列の方が高精度だというのは個人的には意外でした。この傾向は表2で、Keywordへのクエリ書き換えがベースラインより良い結果であることとも一致しています。
タスクまとめ
以上の精度検証実験をもって、クエリ書き換えがある程度有効な手法であることを確認できました。
精度検証後は本番プロダクトへ実装し、このタスクは完了となりました。
感想
ここからは技術的な話ではなく、個人としてこのバイト期間中に感じたこと・学んだことを書き連ねたいと思います。
配属→タスク決定
今回内定者バイトとして AI Shift を志望した動機として、実際のプロダクトの中でのRAGを触ってみたいというものがありました。
RAGが今後欠かせない技術であるともてはやされる中で、普段の研究ではRAGを扱う機会は少なく、たまに読むRAGに関する論文での知識のみがある状態でした。
実際に配属された後は、私の方でかなり自由にタスク案の選定をさせていただきました。
その後、社員の方とタスク案の中からプロダクトの現状などと照らし合わせて実際に取り組むタスクを決定しました。
このプロセスの中で、(わかっていたつもりではあったのですが)実際の課題を考慮してタスクの優先度をつけることや、
そのタスクによって顧客にどんなメリットを与えることができるか、といった視点が足りていないことを感じました。
この辺りはエンジニアとして(社会人として)今後身につけたいです。
精度検証→実装
精度検証については、普段の研究でやっていることとそこまで遠くなく、比較的順調に進めることができました。
一方で本番実装では、開発経験の浅さから学ぶべきことがたくさん見えたように感じます。
内定者バイトの立場としてプロダクト実装をする上で、そもそもレポジトリのキャッチアップから始めなければならないという部分が大変なポイントかなと思います。
Github Copilotでそこまで時間は取られなかったものの、自らのコードリーディングを高めたいと感じています。
また、複数リトリーブするための非同期処理やテストコードの実装など、今まで触れてこなかった (避けてきた) 部分も大変なポイントでした。
その中でも社員の方の手厚いサポートもあり、本番実装をやり切ることができました。
メンターの方はもちろん、チーム全体としてかなり質問をしやすい雰囲気があるように感じました。
そのほか
クエリ書き換えのタスクの他にも、チーム全体で取り組んでいるサーベイタスクに参加させていただきました。
サーベイタスクでは全体の中で担当分の調査を進める中で、自分が理解したことを他のメンバーにどのように伝えるか、どこを切り出して伝えるかという普段の研究では経験できないサーベイの難しさを感じました。
AI Shiftでは新メンバーへの会社全体の概要のキャッチアップの機会が用意されており、会社としてどのような方向で何をしているのか(自分の配属されたチーム以外も)理解が深まったことはありがたかったです。
また、期間中はランチやイベントなど幅広く経験させていただき、内定者バイトならではの理解もできたように感じます。
おわりに
本記事では、RAGの改善に取り組んだ内定者バイトの話を読んでいただきました。
技術的だけではなく、内定者として考えていたこともまとめたつもりです。
ここまで読んでいただきありがとうございました!
明日はアドベントカレンダーの最終日となります。
ぜひご覧ください!!




