こんにちは
AI Shift CTOの青野です
AI Shift AdventCalendar 2024 16日目です
今回はAIエージェントを開発する時の勘所について書こうと思います
お付き合いお願いします〜
はじめに
昨今、生成系大規模言語モデル(LLM: Large Language Model)を活用したプロダクトの開発機会が急速に増えている。ChatGPTやGPT-4など、自然言語による高度な応答を可能とするLLMは、従来困難だった自然言語処理タスクを容易にし、多くの領域で新たなアプリケーションを生み出す可能性を秘めているが、その一方で、LLMを用いたプロダクト開発は、急速に進化するLLMや市場の期待値を受けてより複雑化している
「解決したい課題は何か」「LLMが適切な手段なのか」「データ基盤やセキュリティの要件は満たされているか」「どのようなアーキテクチャを採用すべきか」といった問いは必ず発生する
この記事では、LLMプロダクト開発時に考慮すべき前提・要求・要件定義、設計思想に関する視点を包括的に整理する
AIエージェント開発の前提条件
課題とエージェントの必要性
まず、解決すべきビジネス課題やユーザーニーズを明確化する必要がある。顧客が本当に自然言語で柔軟な問題解決を求めているのか、既存のドキュメントやFAQを活用した単純な問い合わせ自動化で十分なのかを再考すべきである。必ずしもLLMが必須でないケースも多いため、安易な導入は避けるべきだろう
とくに要件定義は必ずしっかりとした時間をとって実施すべき事の一つだ
旧来のプロダクト開発でももちろん非常に重要な項目には違いないのだが、未知への挑戦・研究領域の社会実装という意味合いが強い現状を考えると、プロトタイプの実装を含めた慎重な舵取りが求められる場面は非常に多いだろう
観点としては
- LLMによる解決可能性
- その課題はLLMに適しているか
- 法的問題のクリア
- 人間以外がその課題の解決を実施しても問題ないか
- ラストワンマイルに人間が介在すべきか
- 精度の問題
- LLMによる出力が100%正しくない前提にたった業務に求められる精度の認識合わせ
- 既存システムとの組み合わせ
- LLMが介在するときにどのような組み合わせが最も上手く協調できるか
- リプレイスが必要かどうか
- ユーザーニーズとモデル選定
これらの観点からLLMが介在するポイントを切り出して単体のシステムとして精度検証を行うことが望ましい
AIエージェントによる解決可能性
LLMは万能ではない
確率的な応答に起因する不確実性や、ドメイン固有の厳密な正確性が求められる領域(金融、医療、法律など)では、LLM単独で要件を満たすことが難しい場合がある
ユーザーが期待するのは正確性か、ヒント提供か、対話的な柔軟性か
LLMで本当に課題が解決できるかを事前に検証することが重要となる
全てをLLMに任せる必要は無く、人間のコストを大幅に減らすことでも満たせる要求はあるだろう
このあたりの見極めと期待値の調整が今のフェーズでは求められる
もちろん今後のLLMの進化によって解決可能性の幅は広がっていくことは間違いない
そのためLLMに関わるプロダクトを設計する人間は最新情報のキャッチアップをおろそかにすると致命的な設計ミスをする可能性がある(自戒)
ユーザーニーズとモデル選定
顧客が求める自然言語応答が簡易なFAQ対応なのか、詳細なドメイン知識に基づくアドバイスなのかによって適切なモデルは異なる。モデルサイズ、性能、コスト、オンプレミス運用の可否など、要件に合ったモデル選定が必要となる
多くの場合、専用のLLMが必要なケースは少ない
Gemini1.5やGPT-4oで満たせないほどの性能的な要求は、課題の整理か実現方法が間違えている可能性が高いと思われる
評価額23兆円の規模の会社が作るモデルですら解決できない課題は課題設定が間違えていると考えるのが妥当だろう
ただし以下の場面では一定専用モデルを考慮する価値があるかもしれない
- 低性能で問題がなくコスト面の要求がある場合
- セキュリティ的な制約(オンプレ等)
- 特定のタスクに特化しつつコスト面で圧縮したい場合
- VLM等の学習データに特化する価値がある場合
AIエージェントの要求定義
既存ツールの活用可能性
すでに運用中のSaaSやツールで同等の機能が実現可能な場合、新たにLLMを導入する必然性は薄い
LLM導入にはコストや運用負荷が伴うため、他の選択肢との比較検討が欠かせない
また既存ツールで解決できない場合でも既存ツールとの組み合わせは必須となることが多い
そのツールが
- API連携可能かどうか
- 実現したいことに対して必要なRead/Writeが可能かどうか
- データは適切な形式で構造化されているか
- 前処理やクリーニング、品質保証のプロセスは確立可能か
といったことも検討する必要がある
さらに、個人情報や機密情報を扱う場合には、データガバナンスやコンプライアンス(GDPRや各国法令)への対応も不可欠となる
とくに社内での機密情報を扱うケースでは、データが外部を経由することが許可されるかどうかも検討が必要だろう(この考慮の中で初めてセルフホスティング型LLMの考慮をすれば良い)
UI・UX
AIエージェントは会話を通じた問題解決が主流ではあるが、そのタスクに対してチャット型が適しているかどうかはきちんと考える必要がある
多くの場合チャット型はユーザーに責務を投げすぎている
特に業務に特化する場合テキスト入力は煩雑そのものであり、無駄極まりない
ユーザーはチャットがしたいのではなく、問題解決がしたいのだという点は忘れないようにしたい
AIエージェントの要件定義
上記はあくまで要求定義の段階となり、実際に要件を決めていく場合の勘所を整理する
特に、LLMを中心とした設計なのか、補助に使うのかという部分は非常に重要かつ難易度の高い設計ポイントとなる
LLM依存度の調整
まず前提として昨今のLLMは様々な知識を事前のトレーニングで持っている一方、その知識の正確さ、範囲までは何も提示されていない
つまり動かしてみて検証する必要がある
ただし動いたとしても、ベンダー側で何も保証していない点は注意が必要だろう
そのため、LLMが内包する知識にどこまで依拠するかを明確にし、アプリケーション特有のビジネスロジックやルールとの切り分けを行い、LLMの役割範囲を定義することが必要となる
OpenAI、Google、Anthropicといったベンダーに関して言えば、ある程度LLMにまかせても良い範囲としてはJSON周りが挙げられるだろう
上記ベンダーのLLMは組み込み機能としてJSON Schemaを介する機能があり、JSON Schemaに関して言えば一定信頼をおいても問題ないと考えている
その他のライブラリ・フレームワークに関して言えば非常にリスクが高い(認識しているバージョンの違い等)ためオススメしない
セキュリティ・プライバシー要件
LLM導入には新たな攻撃ベクトル(プロンプトインジェクションなど)が存在する
アクセス制御や認証プロセス、出力フィルタやモデレーション層の導入により、有害なコンテンツや不適切な応答を防ぐ
ユーザーと組織をリスクから守るため、脅威モデリングを含めたセキュリティ設計が必須となる
特に、LLMにDBへ直接クエリを書かせるようなユースケースである場合、通常のアプリケーション設計と同じように、LLMに対するサニタイズのようなものが必要となる
少なくともユーザーの入力によって恣意的にSQLクエリを発行できるような状況は必ず避けなければならないアンチパターンとなる
しかし、まだまだ実稼働しているAI エージェントのようなプロダクトが少ない現状だと、このあたりのセキュリティ的な留意事項に関しては発展途上なのが現状である
AIエージェント時代のアプリケーションと設計
LLMを中心に置いたWebアプリケーションの設計と従来型のWebアプリケーション設計において決定的に異なるのが、主体をシステムに置くかLLMの意思決定に置くかという点にある
意思決定の委譲範囲
従来はシステム側で明確に定義された制御フローが前提だったが、LLM活用によって一部の意思決定をモデルに任せることが可能となる
ただし、その裁量範囲は慎重に設定する必要がある
範囲を狭めすぎると実現可能なユースケースの減少、あるいは利便性の減少というUXの問題にぶつかる
また裁量を与えすぎた場合、ハルシネーションを含めた不確定要素がシステムに致命的な問題を起こす可能性を常に考慮する必要性に迫られる
しかし少なくともLLMに意思決定を委ねる選択をした場合、従来のWebアプリケーション設計と異なる点が少なからずシステム設計に出現する
従来型Webアプリケーションとの違い
今までのWebアプリケーションではユーザーの入力は、システムに適したフォーマットに制限され、入力値が正しい場合のみシステムが決まったフローで処理を行っていた
そのため、設計としては意思決定は既になされている状態でユーザーにオプションを委ねる形で実装されることになる
だが、AIエージェントの開発においては、多かれ少なかれ意思決定がオンデマンドで実行される可能性が高い
それを踏まえてLLMが意思決定に関わる実装パターンを大きく4つに分類してみた
これ以外にもパターンは存在すると思うが、大枠これに収まるのではないだろうか
- システムがユーザー入力からデータベースからデータを取得、LLMにて結果を生成
- LLMがユーザーの入力をシステムに合わせて整形し、システムで結果を取得、LLMにて結果を生成
- ユーザーの入力からLLMが直接必要なAPIを選び入力を整形する
- ユーザーの入力からLLMが直接DBを操作して必要なクエリを発行する
上から順番にLLMの介入度が上がりシステムの安定性も下がっていく
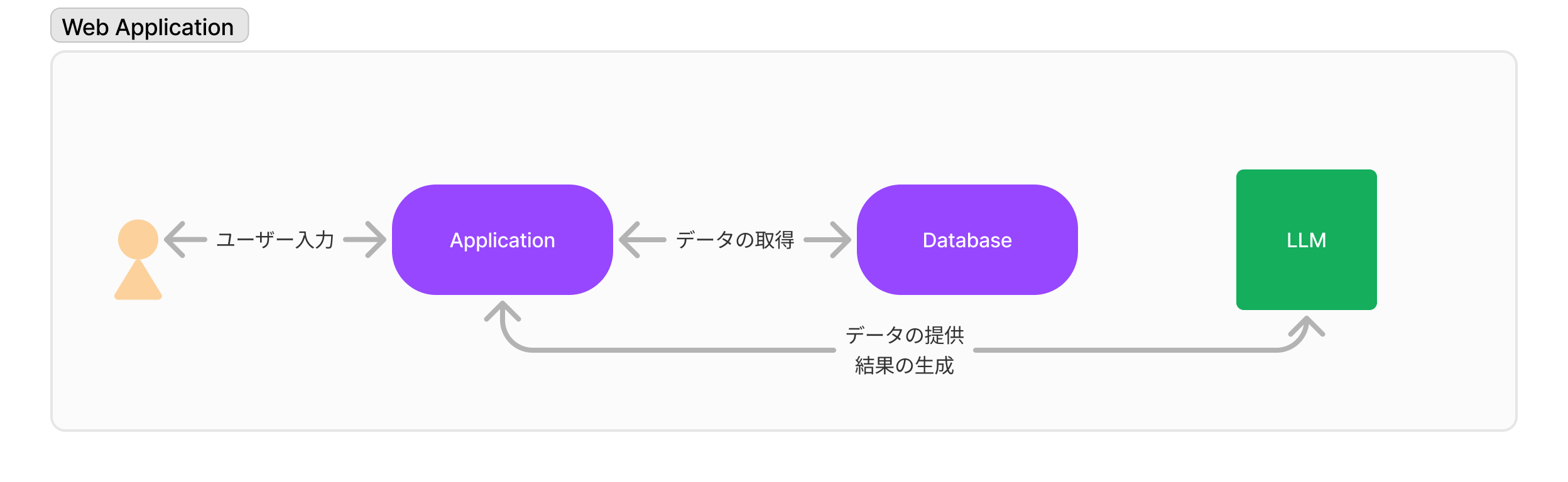
1. 最小関与パターン
これらはシンプルなRAGのシステム等が該当する
DBからのデータ取得は定型のクエリが決まっており、SQL Binding等で値を渡す
入力値もシステムから受け取るだけ
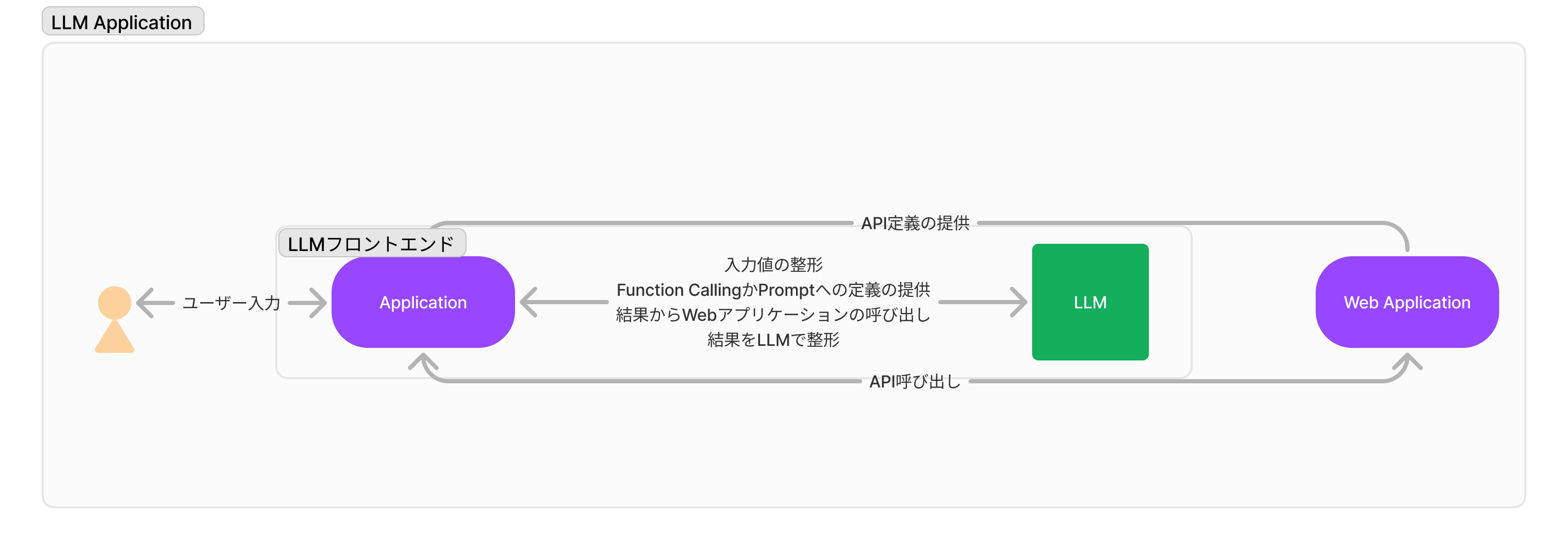
2. Function Callingパターン
入力値から必要な値を取得しAPI向けに整形するパターン
Vector Searchではなく構造化されたクエリのためにユーザー入力を抜き出す
いわゆるFunction CallingでLLMを活用するパターン
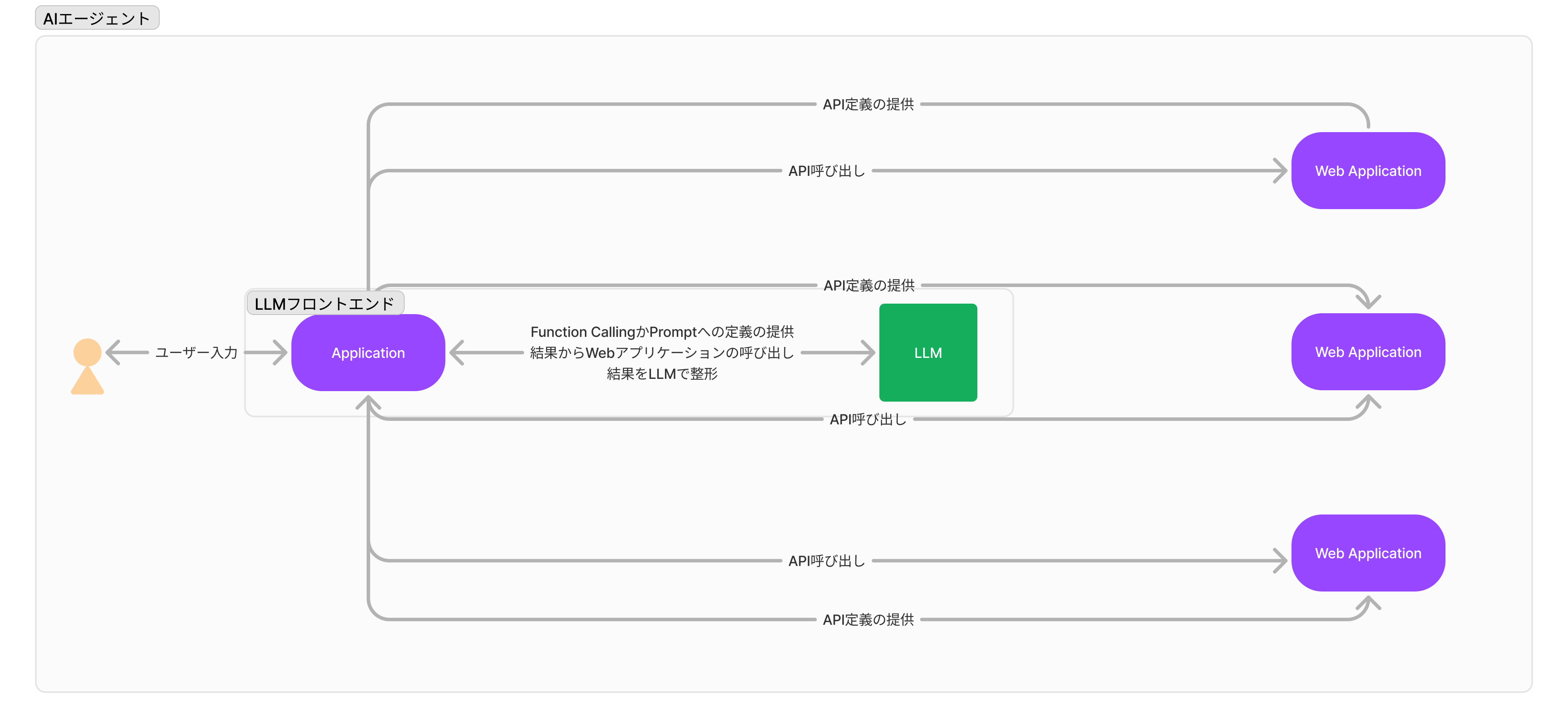
3. AIエージェントパターン
いわゆるAIエージェントという領域
API定義を事前にLLMに提供し、必要なAPIの選択、足りないパラメータの保管を対話で行わせる
最終的に呼び出すAPI、パラメータはLLMによって選択される
ただし、APIを実際に呼び出し、結果を整形する責任はシステムにある
ModelContextProtocol (MCP) と外部知識活用
Model Context Protocol(MCP)は、Anthropic社が開発した、AIアシスタントや大規模言語モデル(LLM)を外部データソースやツールと接続するためのオープンスタン ダードである
これにより、AIシステムはコンテンツリポジトリ、ビジネスツール、開発環境など、多様なデータソースとシームレスに連携できる
MCPに関しては当社のテックブログでも何回か言及されているので、詳細はそちらに譲るとして
【AI Shift Advent Calendar 2024】MCP ClientをOpenAIモデルで実装する
【AI Shift Advent Calendar 2024】MCP(Model Context Protocol)を用いた予約対話AIエージェントの構築と動作のトレース
MCPがなぜ提唱されたのか、どういった利便性があるのかをパターン3から解説していこう
MCPの価値
「MCPは上記のパターン3を提供するためのプロトコルである」というのはやや間違えている
パターン3を実現するだけであれば、AIフロントエンドがAPI定義を単純にLLMに渡せば実現自体は可能であり、難易度としてもさして高いものではない
MCPが提供する価値は「関心の集約」これに尽きる
従来型の欠点
パターン3でのAIエージェント実装には非常に大きな問題が存在しており、それは呼び出すシステムが増えたときに顕著となる
API定義と実装の分離
実装とは別にAPI定義を管理する必要があるため、変更コスト・実装コストが高くなる
API定義に適したプロンプトの変更
API定義だけではなく、プロンプトの変更も管理を別で行う必要がある
MCPの解決方法
MCPではLLMに提供される機能をServerという仕組みで集約して管理を行う
各集約にはresources/prompts/toolsを取得する仕組みが定義されており、各集約のDiscoveryを提供している
この集約のアーキテクチャによって、パターン3の問題を解決することが可能となる
つまり、
サーバが実装とLLM向けの定義、プロンプトが集約して管理されるため、実装・定義・プロンプトこの3つをサーバ側にて提供する事が可能となる
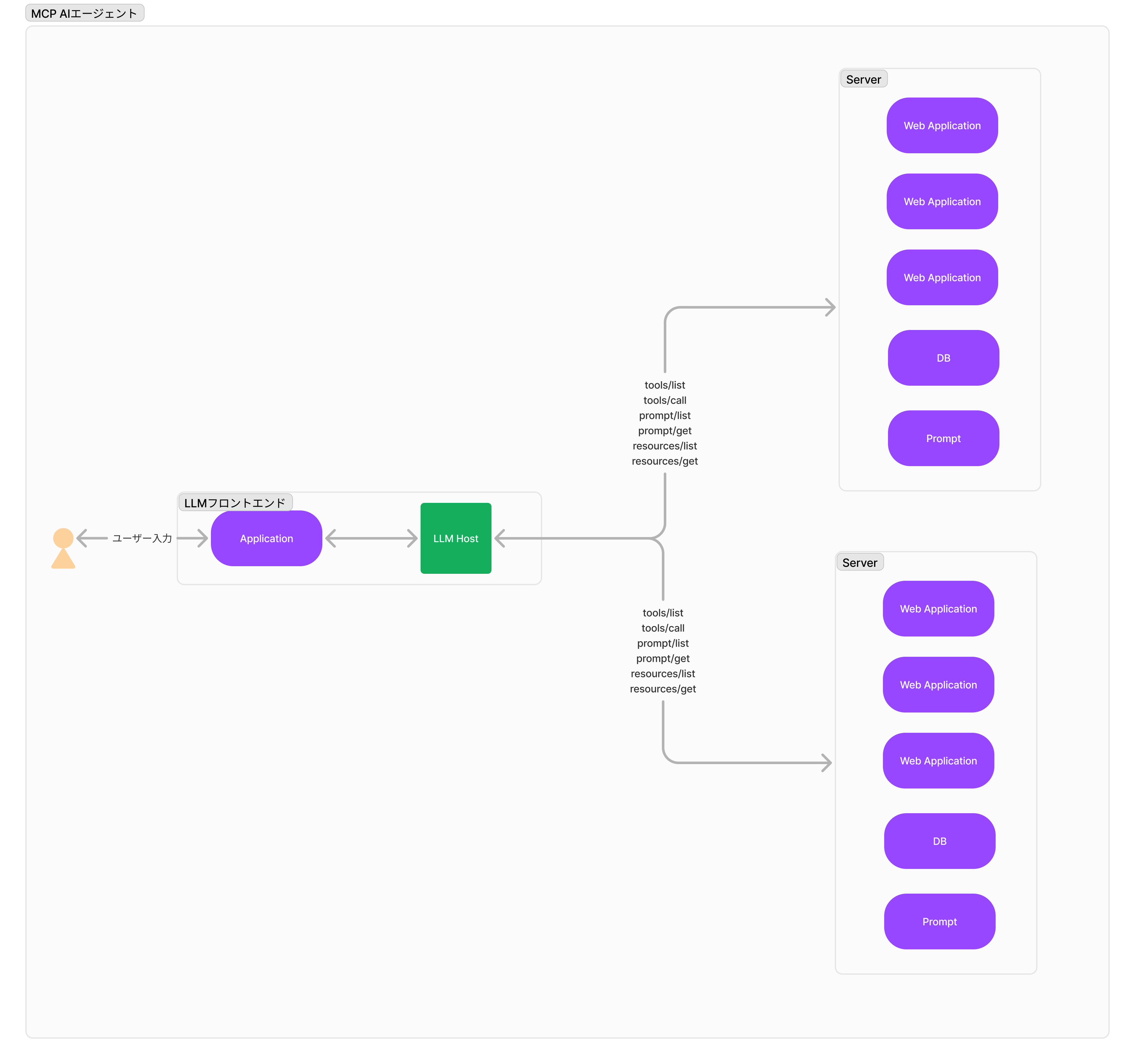
この集約の仕組みをオープンプロトコルにしたおかげで、Server側でMCPに則ったDiscoveryを提供すると、AI エージェントは個別の実装の必要なく機能を増やしていくことが可能になる
MCPの現実とこれから
MCPはあくまで定義であり、アーキテクチャのプロトコルではあるものの
https://github.com/modelcontextprotocol
こちらにTypeScriptやPythonの実装が定義されており、コミュニティ側での様々なServer実装が用意されている
問題点
対応LLMがAnthropicのClaudeのみ
Claude Desktopのみがネイティブで対応しているが、それ以外のLLMだとアプリケーション側の介入がそこそこ必要なので、まだ本領発揮は難しいだろう
OpenAIやその他ベンダーがどれだけ参加するか次第
Server実装の質
あくまでコミュニティ実装であり、実装の質はまばらなので使う前によく内部を確認する必要がある
特にDBに対するWriteアクセスには慎重になった方が良い
実装と定義の分離
コミュニティによるServer実装はMCPのあり方との矛盾が生じてしまう
MCPにて最も重要な点は実装・定義・プロンプトの集約にあるが、少なくともコミュニティ実装の場合実装以外とその他が分離してしまう
本来これらは実装ベンダーが提供することで本当の価値が生まれる
とはいえこれまでもコミュニティがベンダーの補完をしてきた歴史があるのは事実で、コミュニティとベンダーのLLM向けのアーキテクチャで協調する未来がまた生まれるとよいなぁと思う次第
このような共通仕様は最終的には賛同ベンダーの数とパワーバランスが全てなので今後に期待しつつ変なことにならないといいなぁと思っている
理想的なパターン
MCPかどうかは置いておいて、特定のプロトコルにLLMベンダー、クラウドベンダー、SaaSベンダーが参画しAIエージェントの世界に向けて動く
駄目なパターン
各社バラバラなプロトコルを提唱し始めて、10年後くらいに統一する委員会を発足し標準化作業が始まる
個人的にはJavascriptやDOMの標準化までの長い道のりを見てきたので、駄目なパターンのある程度マシなやつに落ち着くのかなぁとは思っている
まとめ
AIエージェント時代のプロダクト開発は、モデル選定やデータガバナンス、セキュリティ、アーキテクチャ、そしてMCP(ModelContextProtocol)による集約の管理など、多面的な視点を要求する
鍵となるのは「なぜAIエージェントを使うのか」という問いへの明確な答えであり、その上で適切なデータ、アーキテクチャ、セキュリティ戦略を整えることが不可欠となる
AI Shiftではこのような観点でより高品質で「ユーザーにとって価値のある」AIエージェント実装を目指すべくプロダクト開発を行っていますのでご興味がある方は是非〜
採用
AI Shiftではエンジニアの採用に力を入れています!
少しでも興味を持っていただけましたら、カジュアル面談でお話しませんか?
(オンライン・19時以降の面談も可能です!)




