こんにちは、AIチームの戸田です。
KaggleのTitanicデータセットは、機械学習の入門として定番のデータセットです。

多くの機械学習手法が試されてきたこのデータセットに対し、今回は少し異なるアプローチを試みたいと思います。ランダムフォレストのような従来の表形式データ向け機械学習手法ではなく、テキストを処理するLLM(Large Language Model)を使って、Titanicの生存者予測を試します。
従来の機械学習手法との比較が容易なこのデータセットを通じて、LLMを使ったアプローチがどの程度の予測精度を発揮するのか、その可能性について共有できたらと思います。
背景
先日、表形式のデータを扱っていた際、カラム名と値のセットをfew-shotとしてLLMに提供すれば、LLMが持つ知識を使って予測できるのではないかと思いつきました。
例えば何かしらのサービスの年ごとの継続/解約を予測したいケースを考えます。以下はユーザーごとの情報が表形式で整理されており、次年度のサービス契約継続可否を予測するシナリオです。
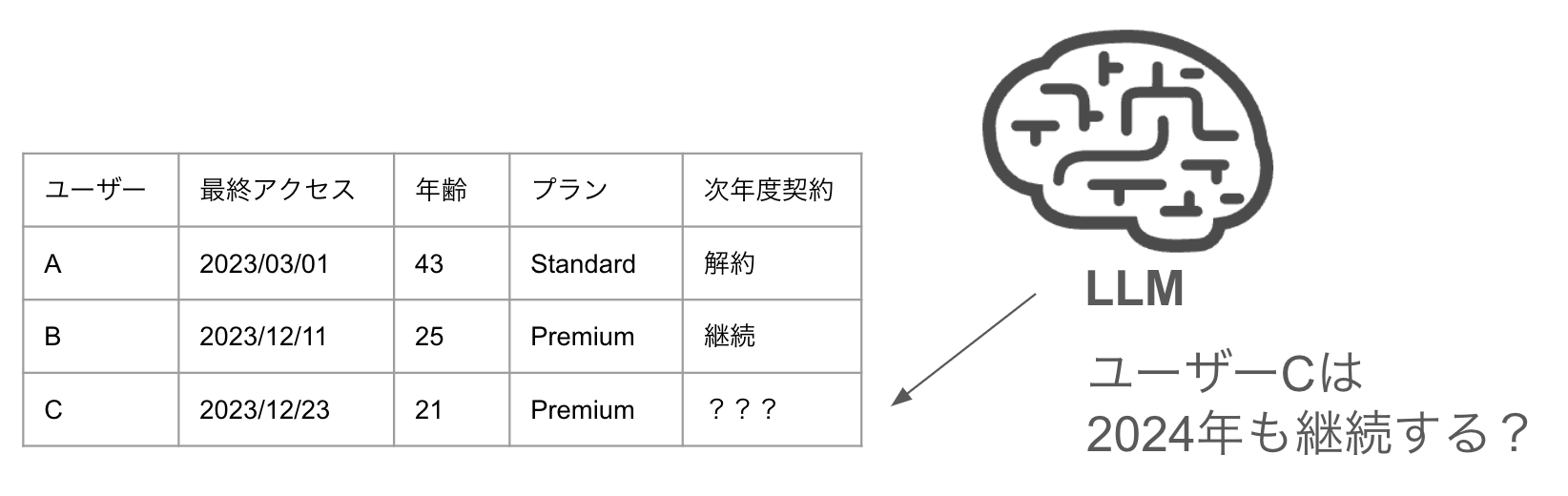
直感的には、ユーザーCはユーザーBの特性に近いため、契約継続の可能性が高いと予測できそうです。しかし実際のデータセットでは、多数の特徴量が存在し、単純な比較だけでは判断が困難なケースが多くなります。
ここで注目すべきは、LLMが学習過程で獲得した幅広い知識です。例えば:
- 「若年層はPremiumプランを好む傾向がある」
- 「最終アクセスが直近のユーザーは継続率が高い」
といった一般的な傾向をLLMは学習している可能性があります。このようなLLMの潜在的な知識を活用するために、few-shotでサンプルを与える方法が有効ではないかと考えました。つまり、いくつかの例(上記の表のユーザーAとB)をLLMに提示し、未知のケース(ユーザーC)について予測を求めるアプローチです。
この方法の最大の魅力は、特徴量エンジニアリングや複雑なモデル構築を行わなくても、LLMが持つ暗黙知を活用できる可能性がある点です。
事例を調べてみると、こういったアプローチに関する研究をまとめた以下のリポジトリを見つけました:
LLM-on-Tabular-Data-Prediction-Table-Understanding-Data-Generation
こちらは表形式データへのLLM応用研究をまとめたもので、few-shotでLLMにサンプルを与えて予測を行う手法も含まれていました。
LLMへのfew-shotでのサンプルの与え方は様々考えられますが、本記事ではこのリポジトリで最初に紹介されていた「Tablet」というベンチマークの形式を使って検証したいと思います。
Tablet

TabletはTABLET: Learning From Instructions For Tabular Dataという論文で提案された表形式データ予測におけるLLM活用の評価を行うベンチマークです。
UCIから取得された20種類の多様な表形式データセットに、様々な言い回し、粒度、技術性を持つ自然言語の指示文を付与しています。 独自のデータセットを定義することも可能です。
環境構築
公式リポジトリのREADMEに従って環境構築を行います。
git clone https://github.com/dylan-slack/Tablet.git
cd Tablet
python3 -m pip install -e .Tabletですが、OpenAI APIにリクエストする部分が古かったのでget_gpt3_revisions関数内の生成結果取得部分(43-52行)を以下のように変更しました
response = openai.ChatCompletion.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": text},
],
)加えて、本記事執筆時点(2025/03/05)の最新版だとmodelパラメータに"chat-gpt" (OpenAI APIを利用)を設定した際の分岐が消えているので、OpenAIの LLMで実験したい際はここも追加する必要があります。evaluate.pyの371行目の下に以下の分岐を追加してください。
elif self.model == "chat-gpt":
self.tokenizer = None
self.model_obj = Noneなお、READMEのサンプルのようにflanなどのHuggingfaceのモデルを利用する際はこの手順は不要です。
Titanic Datasetでの検証
Kaggleのチュートリアルとして有名なTitanicのデータセットを使って LLMでの表形式データの予測を試してみたいと思います。
データ準備
KaggleのコンペティションページからTitanicのデータセットをダウンロードし、任意の場所に解凍します。
欠損値対応など基本的な前処理に加え、目的変数をLLMが扱えるようにテキストに変換します。
import pandas as pd
train_df = pd.read_csv("{解凍した場所}/train.csv")
test_df = pd.read_csv("{解凍した場所}/test.csv")
# 目的変数をテキストに変換
train_df["Survived"] = train_df["Survived"].map({0: "died", 1: "survived"})
train_x = train_df.drop(columns=["Survived"])
train_y = train_df["Survived"].values
eval_x = test_df
eval_y = np.array(["died" for _ in range(len(test_df))]) # testデータの目的変数は未知なので仮の値を置く
dtypes = train_x.dtypes
names_of_categorical_columns = dtypes[dtypes == "object"].index.tolist()
names_of_number_columns = dtypes[dtypes != "object"].index.tolist()
# カテゴリ変数の欠損値は"missing"に変換
train_x[names_of_categorical_columns] = train_x[names_of_categorical_columns].fillna("missing")
eval_x[names_of_categorical_columns] = eval_x[names_of_categorical_columns].fillna("missing")
# 数値の欠損値は-1に変換
train_x[names_of_number_columns] = train_x[names_of_number_columns].fillna(-1)
eval_x[names_of_number_columns] = eval_x[names_of_number_columns].fillna(-1)前処理されたデータをTabletで扱う形式に変換します。
from Tablet import create
# LLMへの指示. コンペティションサイトのOverviewより.
instructions = """The sinking of the Titanic is one of the most infamous shipwrecks in history.
On April 15, 1912, during her maiden voyage, the widely considered “unsinkable” RMS Titanic sank after colliding with an iceberg. Unfortunately, there weren’t enough lifeboats for everyone onboard, resulting in the death of 1502 out of 2224 passengers and crew.
While there was some element of luck involved in surviving, it seems some groups of people were more likely to survive than others.
In this challenge, we ask you to build a predictive model that answers the question: “what sorts of people were more likely to survive?” using passenger data (ie name, age, gender, socio-economic class, etc).
Please answer as either `survived` or `died`.
"""
create.create_task(train_x,
eval_x,
train_y,
eval_y,
name="titanic",
header="You must follow the instructions to predict if passengers had suvived.",
nl_instruction=instructions,
categorical_columns=names_of_categorical_columns,
num_gpt3_revisions=1, # 今回は実験のため1パターンのみ生成
save_loc="./data/benchmark")こちらのコードを実行すると、save_locで指定したディレクトリに変換されたデータがJSON形式で保存されます。以下に変換された1サンプルを示します。
{
"header": "You must follow the instructions to predict if passengers had suvived.",
"lift_header": "",
"class_text": "Answer with one of the following: died | survived.",
"instructions": "The sinking of the Titanic is one of the most infamous shipwrecks in history.\nOn April 15, 1912, during her maiden voyage, the widely considered \u201cunsinkable\u201d RMS Titanic sank after colliding with an iceberg. Unfortunately, there weren\u2019t enough lifeboats for everyone onboard, resulting in the death of 1502 out of 2224 passengers and crew.\nWhile there was some element of luck involved in surviving, it seems some groups of people were more likely to survive than others.\nIn this challenge, we ask you to build a predictive model that answers the question: \u201cwhat sorts of people were more likely to survive?\u201d using passenger data (ie name, age, gender, socio-economic class, etc).\n\nPlease answer as either `survived` or `died`.",
"label": "died",
"serialization": "PassengerId: 109\nPclass: 3\nName: Rekic, Mr. Tido\nSex: male\nAge: 38\nSibSp: 0\nParch: 0\nTicket: 349249\nFare: 7.9\nCabin: missing\nEmbarked: S\n"
}serializationにカラム名とそのデータの値がテキストで入っているのがわかります。このテキストとinstructionsを使ってLLMが予測を行います。
ちなみにlift_headerが空ですが、こちらはinstructionsを指定しない際にalternate_headerという引数から生成されるようなので、instructionsが指定されていれば問題ないです。(こちら、READMEに記載がなく、コードの該当部分のコメントから読み取ったので間違いがあればご指摘いただきたいです)
LLMの予測を作成
Tabletはevaluateという機能を使って評価を行うことができます。使用するLLMは基本的にgpt-3.5-turboになりますが、synthetic_language.pyの201行目を変更することで任意のOpenAIのモデルを設定することができます。今回の実験ではgpt-4o-miniを設定しました。
from Tablet import evaluate
benchmark_path = "./data/benchmark/performance/"
tasks = [
'titanic/prototypes-synthetic-performance-0',
]
evaluator = evaluate.Evaluator(benchmark_path=benchmark_path,
tasks_to_run=tasks,
model="chat-gpt",
encoding_format="gpt",
results_file="titanic_results.txt", # 結果の出力先
k_shot=1)
evaluator.run_eval(how_many=3) # 予測を3回生成するk_shotでfew-shotで何サンプルデータを与えるか設定します。今回は1, 2, 4, 8について3回予測を生成しました。
実行が終わるとresults_fileで設定したところに出力されるので、それを読み込んでKaggleに提出できる形にします。
df = pd.read_csv("titanic_results.txt", header=None)
k = 1
sub_df = pd.read_csv("{解凍した場所}/gender_submission.csv")
for i in range(3):
sub_df["Survived"] = [int(j == "survived") for j in eval(df[5].iloc[i])]
sub_df.to_csv(f"tablet_gpt_k{k}_{i}.csv", index=None)結果
1, 2, 4, 8のfew-shotの予測結果のスコア(3回の平均)は以下のようになりました。
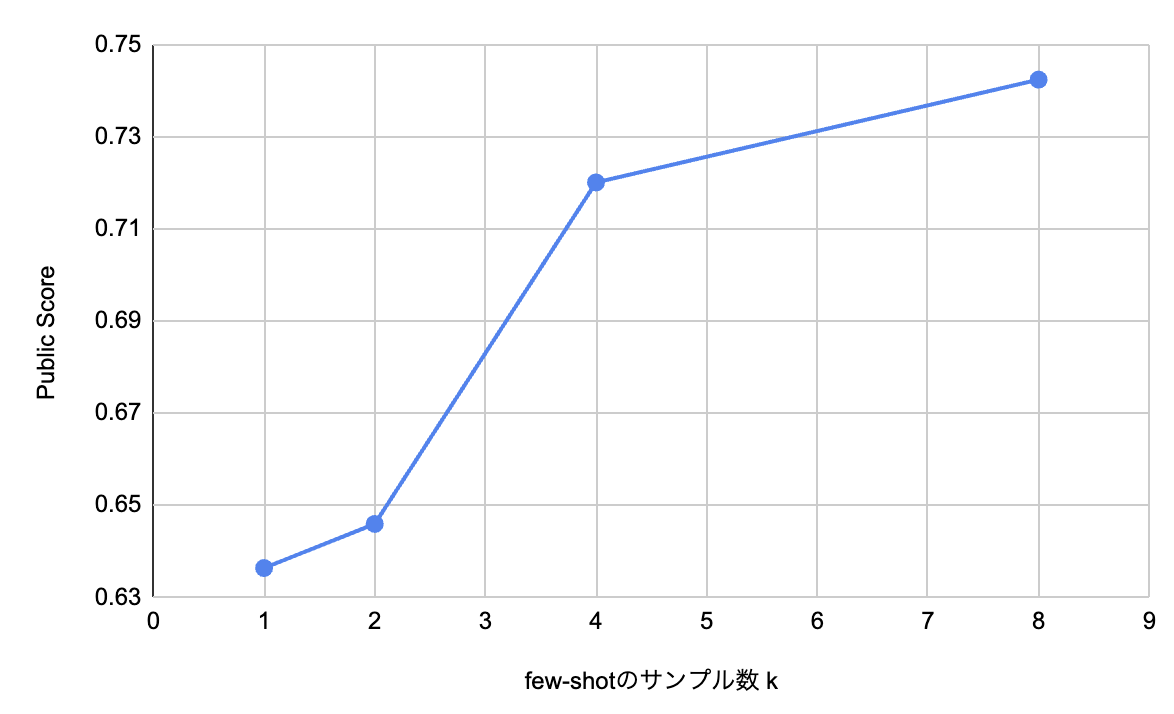
| few-shotのサンプル数 k | Public Score (3回の平均) |
| 1 | 0.63635 |
| 2 | 0.64593 |
| 4 | 0.72009 |
| 8 | 0.74241 |
few-shotのサンプル数を増やすことで予測精度が向上していることが確認できました。
k=8の0.74241というスコアは、こちらの公開Notebookからランダムフォレストを使って学習した予測に近い(0.74162)ことが分かります。これから特徴量エンジニアリングを行わなくても、シンプルなfew-shotで予測を行うアプローチだけで一般的な機械学習モデルに匹敵する性能を達成できたということがわかると思います。
一方、複雑な特徴量エンジニアリングを行うケース(0.83732)や、LightGBMのようなランダムフォレストより複雑なモデルを使うケース(0.82296)には及ばず、few-shotのサンプル数増加とPuclic Scoreの増加の割合を見ても、ここに追いつくことはなかなか難しそうです。
今回のTitanicデータセットを用いた検証で気になった点は、この問題の解法がWeb上に広く存在するため、LLMが既にそのパターンを学習済みである可能性です。よりニッチなデータセットであれば、今回の実験のような少量のサンプルでの問題解決はより困難になると考えられます。なお、今回は実施しませんでしたが、zero-shotでの性能についても今後検証してみたいと考えています。
おわりに
本記事では、表形式データをLLMで扱う研究リポジトリ「Tablet」の紹介と、Titanicデータセットでの LLMのfew-shot予測の事例を検証しました。
LightGBMのような上位の手法と比べれば、まだ性能面で劣る部分は多々ありますが、「特徴量エンジニアリングを最小限に留められる」「学習データが少なくても利用しやすい」といった利点から、工夫次第では今後の重要なアプローチとなり得るのではないでしょうか。
例えば8個という少ないサンプルでナイーブなランダムフォレストと同レベルの予測ができるということは、医療や金融などのプライバシー上の制限から学習データを収集するのが困難な分野で役に立つのではないでしょうか。
加えて先日こちらのポストで紹介されていたような、 GBDT(Gradient-Boosted Decision Trees)の最初の決定木としてLLMの予測を使用する、といった手法も考えられているようです。世界の知識を豊富に獲得しているLLMを「ドメイン知識の入り口」として活用し、それを既存の機械学習モデルに落とし込むハイブリッドなアプローチで非常に興味深いです。
これからも進化の続くLLMの可能性に注目しつつ、表形式データとの組み合わせについてもウォッチしていきたいです。
最後までお読みいただきありがとうございました!




