1. はじめに
こんにちは。AIチームの栗原です。
2025年3月10日(月)〜3月14日(金)に出島メッセ長崎にて行われた言語処理学会第31回年次大会で、弊社からポスター発表で3件、口頭発表で1件の発表を行いました。
昨今の発表件数の増加の流れはさらに続いており、投稿件数は777件(昨年は599件)と過去最高をさらに記録した模様です。自然言語処理への熱はとどまるところを知らないといった様子です!
2. 各発表資料と発表内でのディスカッション
2.1 JHARS: RAG設定における日本語Hallucination評価ベンチマークの構築と分析
発表情報
- Q2:ポスター 3月11日 (火) 10:20-11:50
- Q2-17 ○亀井 遼平, 坂田 将樹 (東北大), 邊土名 朝飛 (サイバーエージェント/AI Shift), 栗原 健太郎 (AI Shift/サイバーエージェント), 乾 健太郎 (MBZUAI/東北大/理研)
発表資料

ディスカッション
研究のFutureWorkになり得るご意見を多数いただきました。ありがとうございます。その一部を紹介いたします。
- ドメインが一般的すぎるような気がする。一番上のamebaの自社データの例のように、LLMの事前学習データに含まれないようなものを参考文献に入れたときや、もっと参考文献の量が多かった時にどうなるのか気になる
- hallucinationの自動検出に関して、推論過程を出力させたり、プロンプトをもう少し工夫したらうまく検出できるようになったりするか気になる。
2.2 タスク指向音声対話における大規模言語モデルを活用した柔軟な発話終了検知の検討
発表情報
- P5:ポスター 3月11日 (火) 10:20-11:50
- P5-15 ○大竹 真太, 東 佑樹, 杉山 雅和 (AI Shift)
発表資料

ディスカッション
- Q: 発話終了と判定するリッカート尺度の評価値の閾値を調整した場合の遅延時間と誤検知率がどうなるか知りたい
- A: LLMが出力するリッカート尺度の評価値には偏りがあります。3以下の予測値については3->2->1の順に計数が多くなっています。本実験では閾値を3に設定した場合のみの評価でしたが、これを2や1に変更すると誤検知率は下がり、遅延時間が長くなると推測できます。この閾値についても誤検知率と遅延時間のトレードオフを見ながら調整していく必要があると考えられます。
- Q: 発話チャンク間の秒数を明示的にLLMに与えると性能が改善したりすることはないのか
- A: 入力が音声の場合は発話と発話の間の無音区間についても一応考慮されているとは思いますが、明示的に与えた方が性能が上がるということは十分に考えられます。今後のプロンプトエンジニアリングの参考とさせていただきます。
- Q: VAPと比較はしないのか
- A: 今回の実験は沈黙時間ベースの手法をベースラインとして定めていたので特に比較していなかったですが、今後の課題としてVAPとの比較にも取り組みたいと考えています。
- Q: どれだけユーザ発話が終了する前に発話終了のタイミングを予測するかが重要なのに遅延時間にLLMの処理時間が入ってきてしまうのは良いのか
- A: 予測にモデルの処理時間が入るのは自然なことだと考えています。本実験の場合、沈黙時間ベースの方法をベースラインとしているため、それよりも遅延時間を短縮できたことは成果だと考えられます。学術的には新規性に乏しかったり地味な結果となってしまっているかもしれませんが、実際のプロダクト運用を考えると、本研究の提案手法は十分に検討の余地があると考えています。
2.3 TEPPAY: ゲームのプレイ動画を入力とする実況AI Tuberシステムの提案
発表情報
- P9:ポスター 3月13日(木) 10:20-11:50
- P9-19 ○栗原健太郎 (AI Shift, サイバーエージェント), 吉野哲平, 高市暁広, 岩田伸治 (サイバーエージェント), 長澤春希 (AI Shift), 佐藤志貴, 岩崎祐貴 (サイバーエージェント)
発表資料
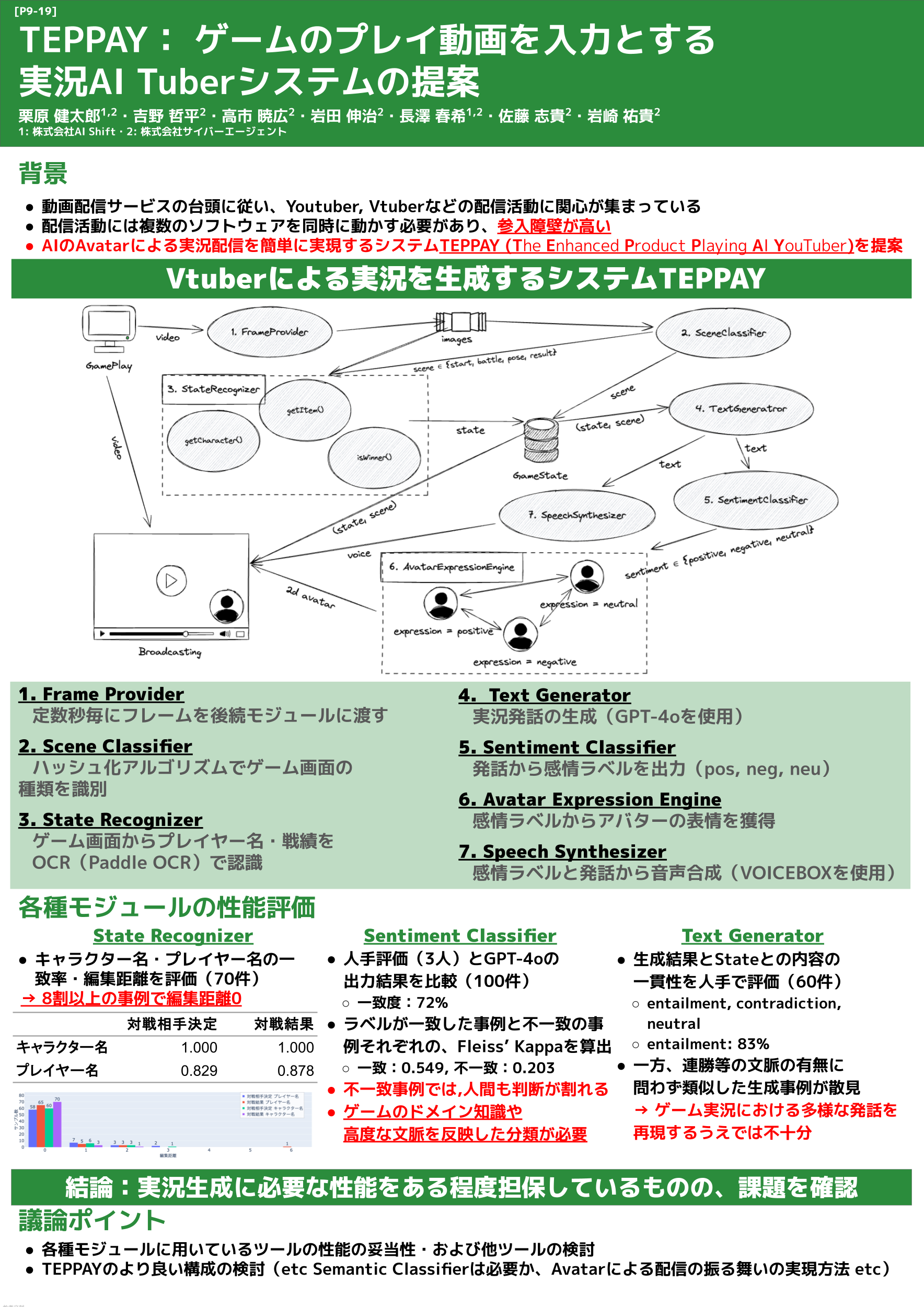
ディスカッション
システムのクオリティ向上に向けたご意見を多数いただきました。その中から一部を抜粋して紹介いたします。
- ゲームの画面の状態はある程度GameStateで保持できていそうだが、プレイ内容自体はStateに保存できていない、つまりそれを考慮した発話もできていなそう。そこで、Vision-Language-Model (VLM)の活用を提案したい。ただし、リアルタイム性を保持するという観点から、状況を表すラベルなどの単語を生成して、発話のヒントとして与えるのが良さそうに見える
- テキストの発話について、VTuberのようにユーモア混じりの面白さを実現していくのは少し難しいように感じる。一方で、状況説明などがある程度できそうに見えるので、スポーツ実況・将棋実況などの場況を説明しながらの実況などは向いているかも。
- 1人での実況はどうしても、単調になりがちかも。いっそLLM同士を対話させることで、2人実況のような枠組みにすると、より幅が広がるのではないでしょうか。
2.4 多面的なユーザ意欲を考慮したセールス対話データセットおよび対話システムの構築と評価
発表情報
D4:テーマセッション2: 人とAIの共生に向けた対話システム・言語使用の研究(3) 3月11日 (火) 14:50-16:20 D4-2 ○邊土名 朝飛, 馬場 惇, 佐藤 志貴 (サイバーエージェント), 赤間 怜奈 (東北大)
発表資料
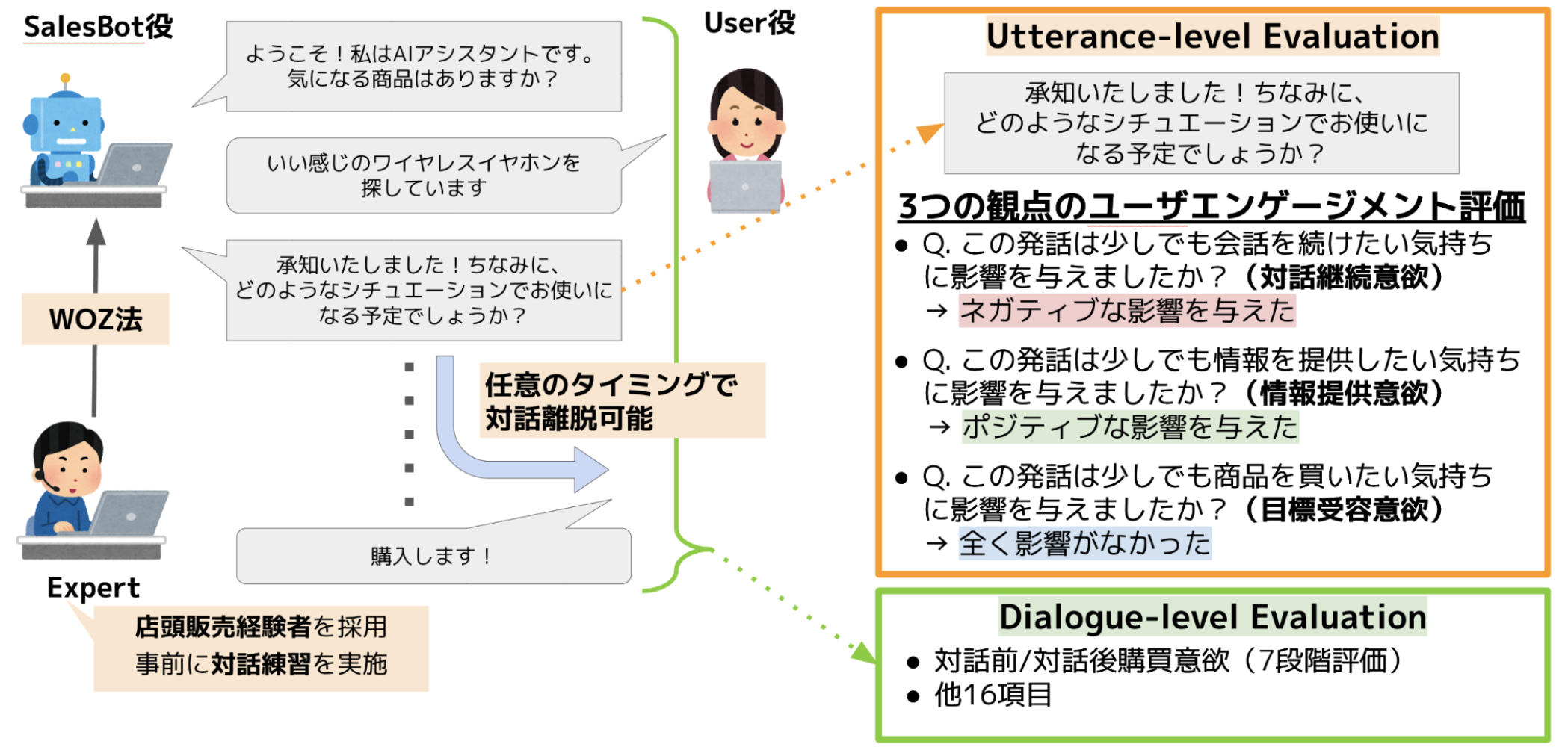
ディスカッション
- Q: 対話の最初はユーザからされるのでしょうか?対話をしようとする段階で購買意欲は高い状態でスタートするというバイアスはないのかと気になりました。
- A: 必ずセールス側から対話を開始する設定で行いました。事前購買意欲バイアスに関してですが、前提として「商品に多少興味はあるユーザ」を想定しておりまして、全く購買意欲がないユーザはセールストークの対象外としています。
- Q: 詳細な説明を求めているとか対話を求めてるユーザにのみ対話をするみたいな戦略が必要なのかもしれないですね
- A: 確かにそのような戦略も必要かもしれません。ちなみにベテランの店頭販売員の方々にヒアリングすると、「相手の動き、視線、見ている商品、他にどの商品を見ていたかを考慮して話しかけるか否かや声掛け内容を変えている」とのことでした。テキストチャットの内容だけでこのような戦略を決定するのは難しいかと思いますので、発話(テキスト)だけでなくマルチモーダルな情報を考慮した対話システムが必要だと考えています。
- Q: 意欲が高くなる発話の傾向があれば教えていただきたいです。
- A: 明確にこうした傾向がある、とは言いにくいのですが、以下の2つの傾向があると思います。①質問は基本的にセールス側から行い、ユーザのニーズを把握する & ユーザ側から想定していない質問がされることを防ぐ②漠然とした質問など、ユーザの回答コストが高い質問を行わない(②の回答コストが高い質問の例:どんな商品をお探しですか?、②の回答コストが低い質問の例:仕事と趣味(映画鑑賞や音楽鑑賞など)のどちらの用途で使用されることが多いでしょうか?)
3. おわりに
NLP2024, YANS2024に続いて、生成AIの台頭に起因した評価やデータセット構築の動きは今年も盛んなように感じました。たとえば、事業者として関心が高いRAG一つをとっても、表の上手い扱い方などその幅は多岐にわたっていました。 また、横井先生らのチュートリアルにもあるとおり、モデルの振る舞いに着目する流れもかなり盛んになりつつあると感じました!出力結果に着目している事例や、モデルのレイヤーに着目するなど多く見られたように感じます。(受賞論文もそういったものが多かったでしょうか?)
LLMいずれにせよ、一見してなんでもできてしまいそうに見えるLLMを解き明かすという動きがより加速しているように実感しました!
最後に、このような素晴らしい学会を開催頂いた運営の皆様に感謝申し上げます。
来年は宇都宮開催が発表されました。宇都宮と言いますと、栗原は小学校の修学旅行で行ったのが最後になりますので、15年ほど前の記憶を掘り起こしながらの参加になるかなと思います!(尚、ほぼ記憶なし) 来年もあわよくば尖った研究発表ができれば!とも考えておりますので皆様よろしくお願いいたします。




