はじめに
こんにちは、AIチームの大竹です。
2025年4月6日(日)〜4月11日(金)にインド・ハイデラバード、Hyderabad International Convention Centreにて開催された、音響・音声・信号処理分野における世界最大の国際会議である第50回 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2025) に同じくAIチームの長澤とともに参加し、弊社から1件の研究発表を行いました。
今年は記念すべき50周年の開催となり、投稿論文数は6947件、採択論文数は3145件(採択率45.3%)と、この分野への注目度の高さが伺えました。また、今回の会議では、ビザ取得の都合などさまざまな理由により、ポスター発表でのno showや口頭発表での事前録画ビデオの上映が多く見られました。

学会の様子
開催地インド・ハイデラバードへの渡航は、シンガポール経由で約15時間かかりました。Rajiv Gandhi国際空港から学会会場まではタクシーで約1時間でしたが、道路状況や常にクラクションが鳴り響く交通事情は印象的でした。
学会会場は広く、ポスターセッションや企業ブースも活気がありましたが、前述のビザ問題の影響で発表者が不在のセッションも見受けられました。
学会イベントとしては、Welcome Receptionが開催され、インドの伝統武術「カラリ・パヤット」や、映画『RRR』の「Naatu Naatu」を含むインドダンスのパフォーマンスが披露され、現地の文化に触れる貴重な体験となりました。
発表内容とディスカッション
Task Vector Arithmetic for Low-Resource ASR
発表情報:
- セッション:Poster 3C
- 発表日:4/10 11:30 〜 13:00 (インド, ハイデラバード現地時間)
- 著者:⚪︎Haruki Nagasawa (AI Shift), ⚪︎Shinta Otake (AI Shift), Shinji Iwata (CyberAgent)
- 論文リンク
発表資料
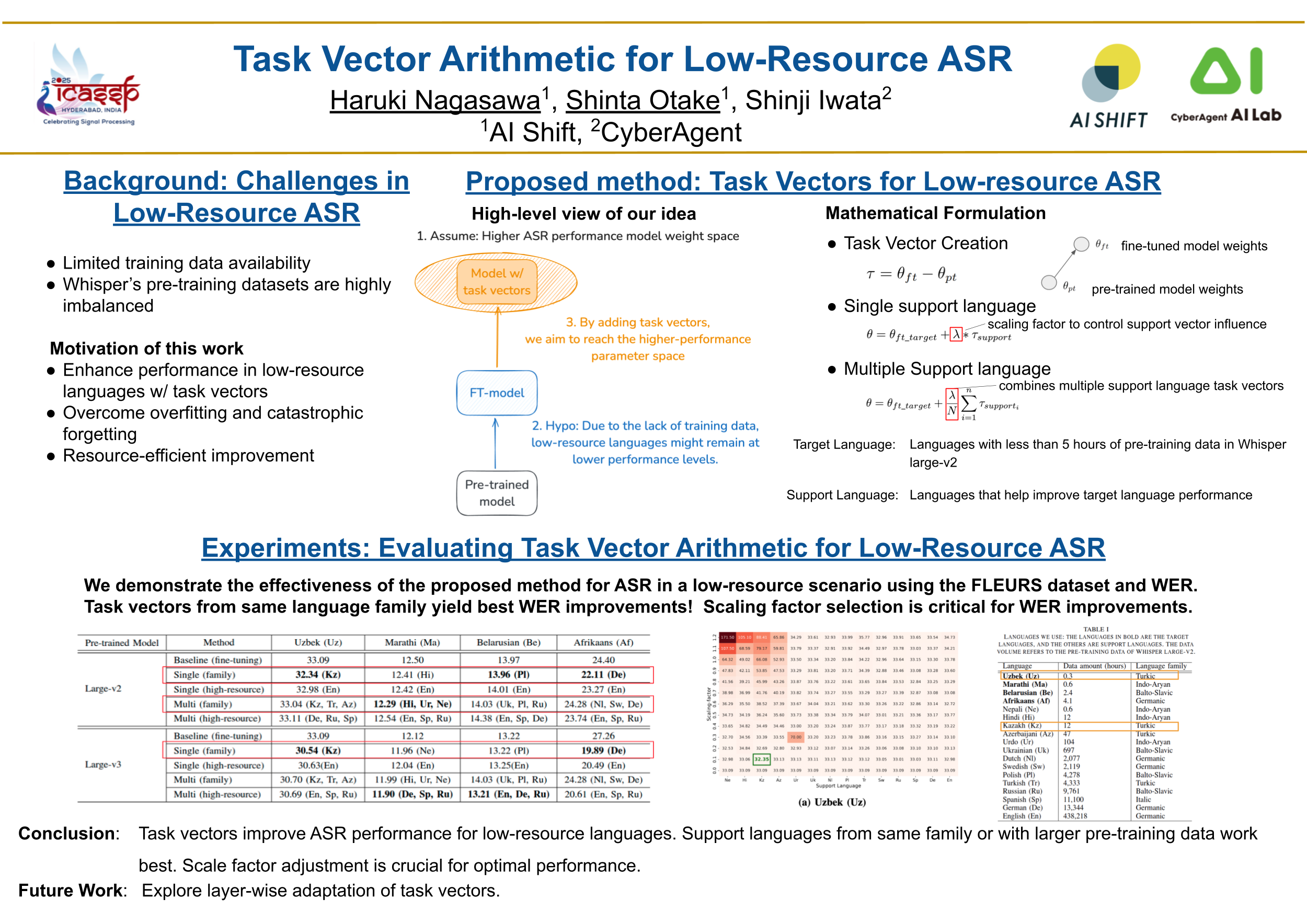
研究概要
本研究では、task vectorを活用し、データ拡張を用いずに低資源言語における自動音声認識(ASR)の性能を向上させる手法を提案しました。具体的には、事前学習済みのASRモデルと、ターゲット言語の性能向上を手助けするサポート言語でファインチューニングしたモデルからtask vectorを計算し、それをターゲット言語でファインチューニングしたモデルに加算します。実験の結果、同じ語族の言語から生成したtask vectorを用いることで、ターゲット言語のWER(Word Error Rate)が最も改善されることが示されました。
なお、本研究ではターゲット言語は事前学習済みASRモデルにとって学習データ量が5時間未満の低資源言語としています。
ディスカッション(主なQ&A)
- Q: task vectorとは具体的に何を指すか? また、task vectorを作成するためにも追加の学習が必要か?
- A: task vectorは、事前学習済みモデルの重みと、特定のタスク(ここではサポート言語のASRタスク)でファインチューニングした後のモデル重みの差分ベクトルです。このtask vectorを任意のパラメータに加算することによって、特定のタスクの能力を付加することができます。なお、task vectorの作成にはサポート言語でのファインチューニングが必要です。
- Q: task vectorをどの程度反映させるかを調整するscaling factor λは、どのように決定したか?
- A: 本研究では、FLEURSデータセットの検証セットを用いてグリッドサーチを行い、最適なscaling factorを決定しました。
- Q: 最適なサポート言語の組み合わせは、どのように見つけたか?
- A: ターゲット言語と同じ語族内で1〜3言語、または全言語中でデータ量が多い上位1〜3言語をサポート言語の候補として選択しました。これらの候補についてtask vectorを適用し、検証セットで最も性能が良かった組み合わせを実験結果として報告しています。
- Q: 提案手法によってどのような理屈でoverfittingやcatastrophic forgettingを防げるのか?
- A: ターゲット言語のデータのみでファインチューニングすると、限られたデータにモデルが過剰適合しやすくなります。しかし、事前学習済みモデルのパラメータを基準点として、関連するサポート言語への適応方向を示すtask vectorを加えることで、パラメータがターゲット言語の狭い最適解に陥るのを防ぎ、より汎化された、あるいは事前学習時の知識を保持しやすいパラメータ空間へと誘導する正則化のような効果があると考えています。
- Q: 言葉ではない音声、例えば笑い声、泣き声、フィラー(「あー」「えーと」など)といった非言語的な音声にも適用可能か?
- A: 本研究では、主に低資源言語における単語の認識精度向上に焦点を当てておりました。そのため、笑い声のような非言語的な音声の認識に対して、提案手法を直接テストしてはおりません。しかし、概念的には、特定の非言語音(例:笑い声)を認識するタスクを定義し、それに対応するtask vectorを計算し、活用できる可能性はあると考えています。
- Q: 英語やドイツ語のような高資源言語(rich language)同士の組み合わせで適用した場合、どのような結果が期待できるか?
- A: 本研究では主に低資源言語の性能改善を目的としていたため検証はしていませんが、高資源言語は元々の性能が高いため、別の高資源言語のtask vectorを加えても改善の余地は小さく、性能向上は限定的だと考えています。
終わりに
ICASSP 2025では、近年のLLMの目覚ましい発展を受け、その技術を音声処理に応用しようとする研究や、応用に伴う課題解決を目指す研究が数多く発表されていました。一方で、音声処理には幅広いタスクがあるため、タスクに特化したアーキテクチャの探求も依然として活発に行われており、LLMが必ずしもデファクトスタンダードとなっていない現状は、音声処理分野が今まさに発展途上であり、取り組みがいのある分野であることを改めて実感しました。
ポスター発表においては、世界各国から集まった第一線の研究者の方々と直接、有意義な議論を交わすことができ、大変貴重な経験となりました。
今回発表した研究は、サイバーエージェント社内のゼミ制度における活動から生まれた成果です。この経験を糧とし、今後はAI Shiftのメンバーとして、事業に直結する課題解決に貢献できる研究開発に取り組み、国際学会への投稿を目指して精進して参ります!
最後にこのような素晴らしい学会を開催・運営してくださった関係者の皆様に心より感謝申し上げます。




